ClickHouse CDC with Field-Level Updates
One field changed—why rebuild the whole object? With field-level CDC in ClickHouse, you update only what’s new and keep the full history.
The Pain of Full-Object Syncs
In many data pipelines, the go-to method for keeping downstream systems up to date is “just sync the full object” whenever something changes.
If you’re lucky, that object lives entirely in one source, so you can simply re-fetch it. But in most real systems, a “full object” is actually stitched together from multiple upstream systems:
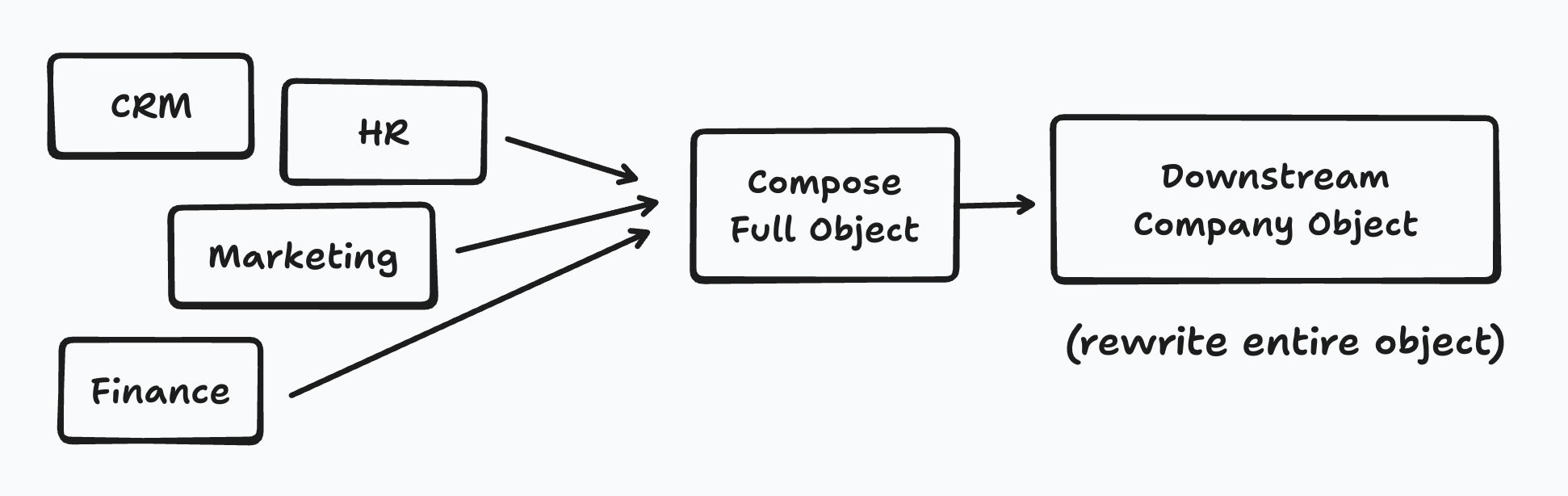
- CRM for contact info
- RP for billing
- Marketing DB for campaigns
- HR or finance systems for headcount and revenue data
That means when you want to update just one field, you end up either:
- Overfetching — hitting every source, reassembling the full object, and pushing it downstream, or
- Suffering during backfills — running expensive multi-source joins just to fix a single attribute.
A Quick, Painful Reality Check
You find a typo in the _employee_count_ in your HR data for 1,200 companies. With a full-object sync, you now must:
- Pull from _all_ upstream systems to rebuild the company object for each record
- Rewrite every field — even though 99% are unchanged
- Risk overwriting fresh updates from other sources
Result: wasted compute, slower jobs, higher storage churn, and higher risk of data corruption.
A Better Way: Field-Level Change Data Capture
Instead of treating “the object” as the atomic unit, treat **each field change** as the atomic event. A change to `employee_count` becomes its own row:
object_id: 42
object_type: "company"
field: "employee_count"
value: "350"
timestamp: 2025-08-09T09:15:32Z
This means:
- A backfill for employee_count only touches that field for affected rows.
- You don’t need to touch other fields or reassemble the object.
- Late or out-of-order updates are handled naturally.
Designing a Solution in ClickHouse
We’ll use three layers in ClickHouse:
- Raw change log (append-only, one row per field change)
- Latest value per field (deduplicated by key + version)
- Wide object view (JSON blob + optional materialized columns for hot fields)
1. Raw Change Log
Append every change into cdc_events:
CREATE TABLE object_properties_log
(
object_id UInt64,
object_type LowCardinality(String),
field LowCardinality(String),
value String,
ts DateTime64(3, 'UTC'),
op Enum8('insert' = 1, 'update' = 2, 'delete' = 3),
source LowCardinality(String),
version UInt64 DEFAULT toUnixTimestamp64Milli(ts),
ingested_at DateTime64(3, 'UTC') DEFAULT now64(3)
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(ts)
ORDER BY (object_type, object_id, field, ts);
This is your audit log. It’s append-only and never mutated.
2. Latest Value Per Field
We use a ReplacingMergeTree keyed by (object_type, object_id, field). The highest version wins.
CREATE TABLE object_properties_latest
(
object_type LowCardinality(String),
object_id UInt64,
field LowCardinality(String),
value String,
ts DateTime64(3, 'UTC'),
version UInt64
)
ENGINE = ReplacingMergeTree(version)
PARTITION BY object_type
ORDER BY (object_type, object_id, field);
Keep it up to date via a materialized view:
CREATE MATERIALIZED VIEW mv_latest_into_props
TO object_properties_latest
AS
SELECT
object_type,
object_id,
field,
value,
ts,
toUnixTimestamp64Milli(ts) AS version
FROM object_properties_log
WHERE op != 'delete';
Deletes can be handled by either removing the row or writing a tombstone value.
3. Wide Table as JSON
Rather than pre-pivoting into hundreds of columns, store a JSON object per entity, plus materialized columns for the most queried fields.
CREATE TABLE companies_wide_json
(
id UInt64,
data String,
name String MATERIALIZED JSONExtractString(data, 'name'),
domain String MATERIALIZED JSONExtractString(data, 'domain'),
version UInt64,
updated_at DateTime64(3, 'UTC')
)
ENGINE = ReplacingMergeTree(version)
ORDER BY id;
CREATE MATERIALIZED VIEW mv_companies_wide_json
TO companies_wide_json
AS
SELECT
object_id AS id,
toJSONString(
mapFromArrays(groupArray(field), groupArray(value))
) AS data,
max(toUnixTimestamp64Milli(ts)) AS version,
max(ts) AS updated_at
FROM object_properties_latest
WHERE object_type = 'company'
GROUP BY object_id;
Query hot fields directly from materialized columns:
SELECT id, name, domain
FROM companies_wide_json
WHERE id = 42;
And pull less-used fields with JSONExtract* functions.
Why This Pattern Works
- No overfetching: Update only the fields that changed.
- Fast backfills: Touch only the target attribute.
- Idempotent: Latest table dedupes by
(key, version). - Auditable: Full history stays in
object_properties_log. - Composable: You can build multiple wide tables (e.g. companies, contacts) from the same latest table.
ClickHouse’s combination of fast ingestion, flexible materialized views, and efficient deduplication makes it an ideal home for this pattern. You end up with the best of both worlds: a complete history for auditing and debugging, and a low-latency “latest state” for serving queries.