Microservices
I like to think of microservices as small single-responsibility applications that communicate via HTTP, TCP, or Message Queue.
When publishing an API for public consumption HTTP and JSON have emerged as the standard. However, my preference for inter-service communication is Protocol Buffers or GraphQL.
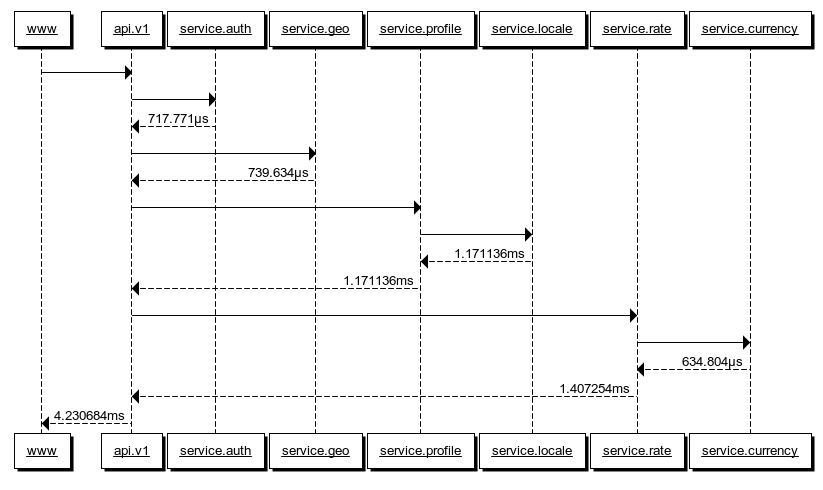
This sequence diagram illustrates an API which takes HTTP/JSON requests and then uses gRPC/Protobufs to communicate between downstream services.
Each service should manage its own datastore. It gives us the flexibility to pick and choose specialty databases based on the functionality of the service. For example, a service that relies on geodata could use Postgres PostGis or any other database specializing in geospatial queries.
Microservices should never share databases, and if the case arises where one service is relying heavily on another for data (HTTP as a database), we should take a step back and evaluate the data boundaries of the services; this can act as an early indicator that two or more services should be merged together.